At Recast, when we’re developing MMM models for our customers, we follow a Bayesian modeling workflow inspired by the process outlined by Gelman et al. (2020).
The goal of course is to build a model that accurately captures the true causal relationships in the underlying data. Specifically, we are interested in estimating the true incrementality of marketing investment. In particular, we want a model that has the following attributes:
-
Is compatible with marketing science theory
-
Is compatible with expert beliefs about marketing performance
-
Is robust to changes in the underlying data
-
Has good out-of-sample forecast accuracy
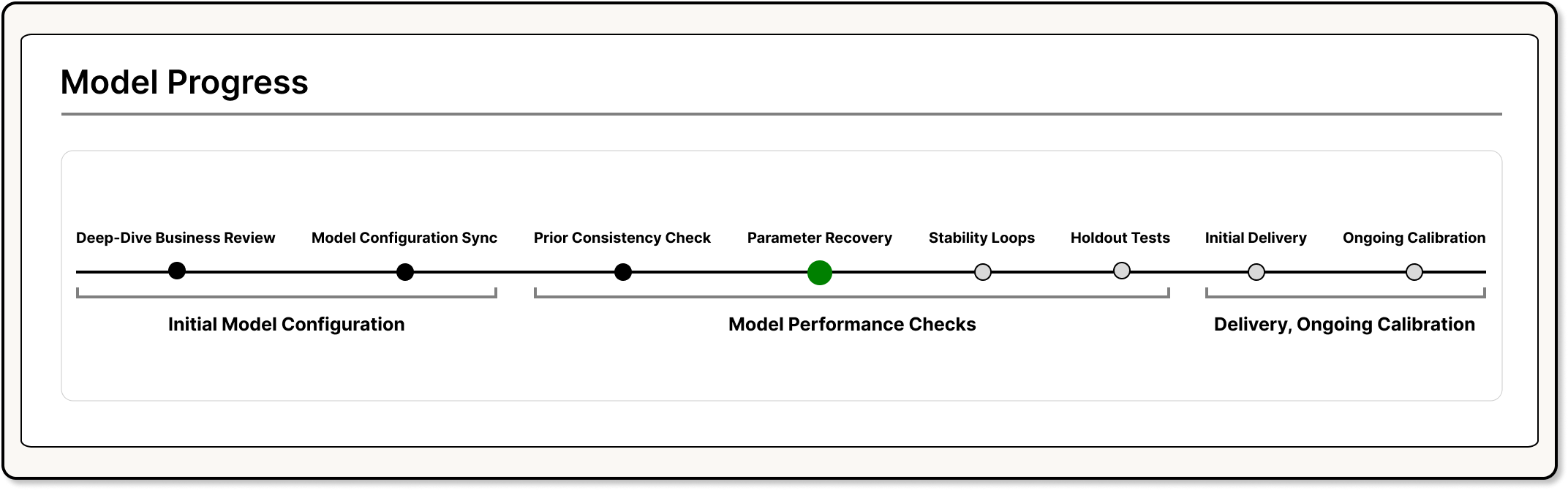
To make sure your model is running correctly, we conduct a series of checks. If your model has passed all the checks, it is ready to draw your initial results. Our model validation workflow has the following steps:
Below, we’ll walk through each of these steps in detail and how they’re performed in the Recast context.
Prior Consistency Check
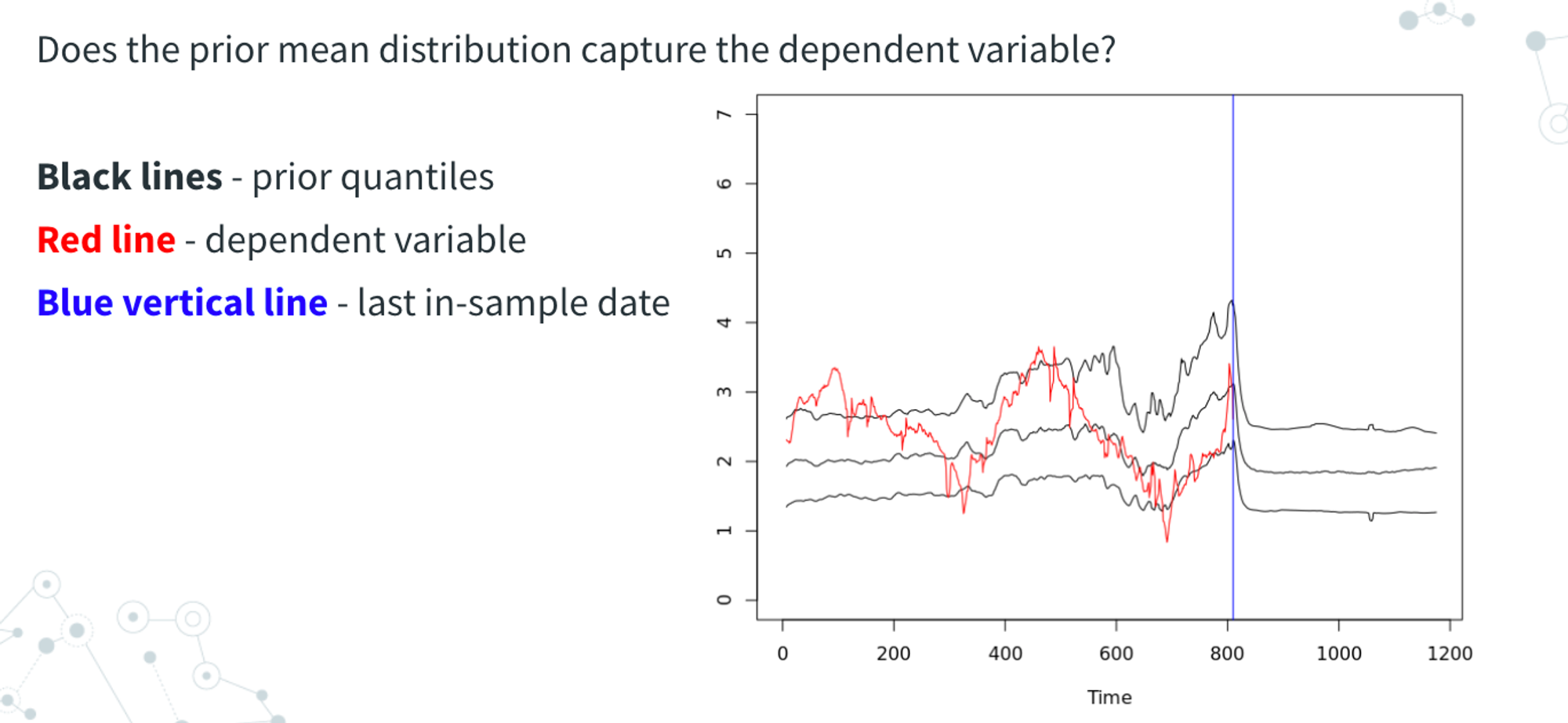
As a first check, we want to make sure that the priors are at least plausibly consistent with the data we are modeling. We want to perform the following checks:
-
Given the set of priors we have, what are the ranges that the dependent variable(s) can take on?
-
Do the actuals fall within the range of values that are expected with the values set by the priors?
Parameter Recovery
Next we want to make sure that the model is capable of getting to the truth when we know what the answer is. This helps us identify places where either (a) the model is misconfigured or (b) the internal structure of the data makes certain parameters difficult to identify (i.e. due to multicollinearity in marketing spend).
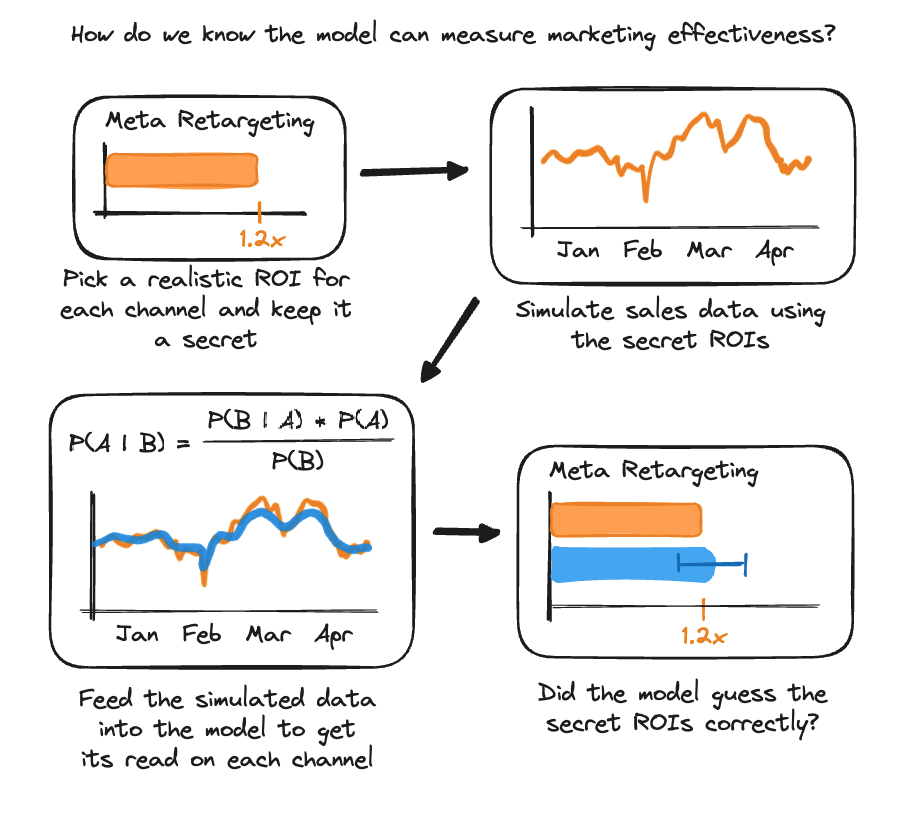
To perform a parameter recovery, Recast will:
-
Select a random value for all of the parameters from the priors
-
Generate dependent variable(s) using those selected parameters as if they were the truth
-
Run the model using the fake dependent variable(s)
-
Confirm that the posterior parameters (the results of the model) match the parameters selected in step 1
Example: ROI Parameter Recovery: In this example, we can see that the model did a pretty good job (not perfect!) of capturing the major swings in the channel’s ROI over the course of the time series.
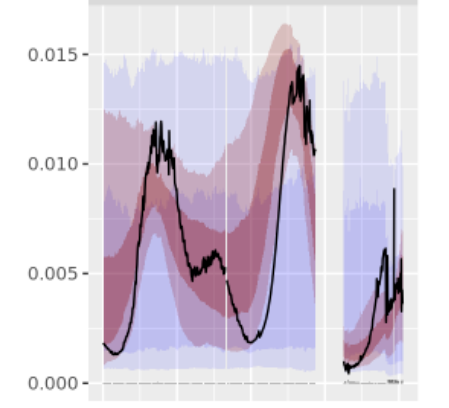
Red shaded area: posterior
Black line: the "true" parameter value
Stability Loop
Now, it’s time to start testing the model with real data. One pathology that is indicative of underlying model issues is parameter instability. If we only slightly change the underlying data and the estimated parameters swing wildly, it probably means that there is some sort of gross model misspecification that is leading the model to bounce between different possible (but inconsistent) parameter sets. We want to identify this before a customer makes any decisions off of the model’s results.
The way we check for model stability is to run the model on subsequent subsets of the data each with an additional seven days of data and check to make sure the model doesn’t show any major swings in parameters.
Since we update the model every week from scratch, this is a check to see how much the model changes from week to week.
Backwards Holdout
Once the model has passed all of the other checks, we want to make sure that the model can accurately predict the future on data it hasn’t seen before. This gives us evidence (but not proof!) that we have picked up true underlying causal relationships in the data and not just correlations.
We have written a full-length post on how we think about doing good out-of-sample accuracy testing on the Recast blog.
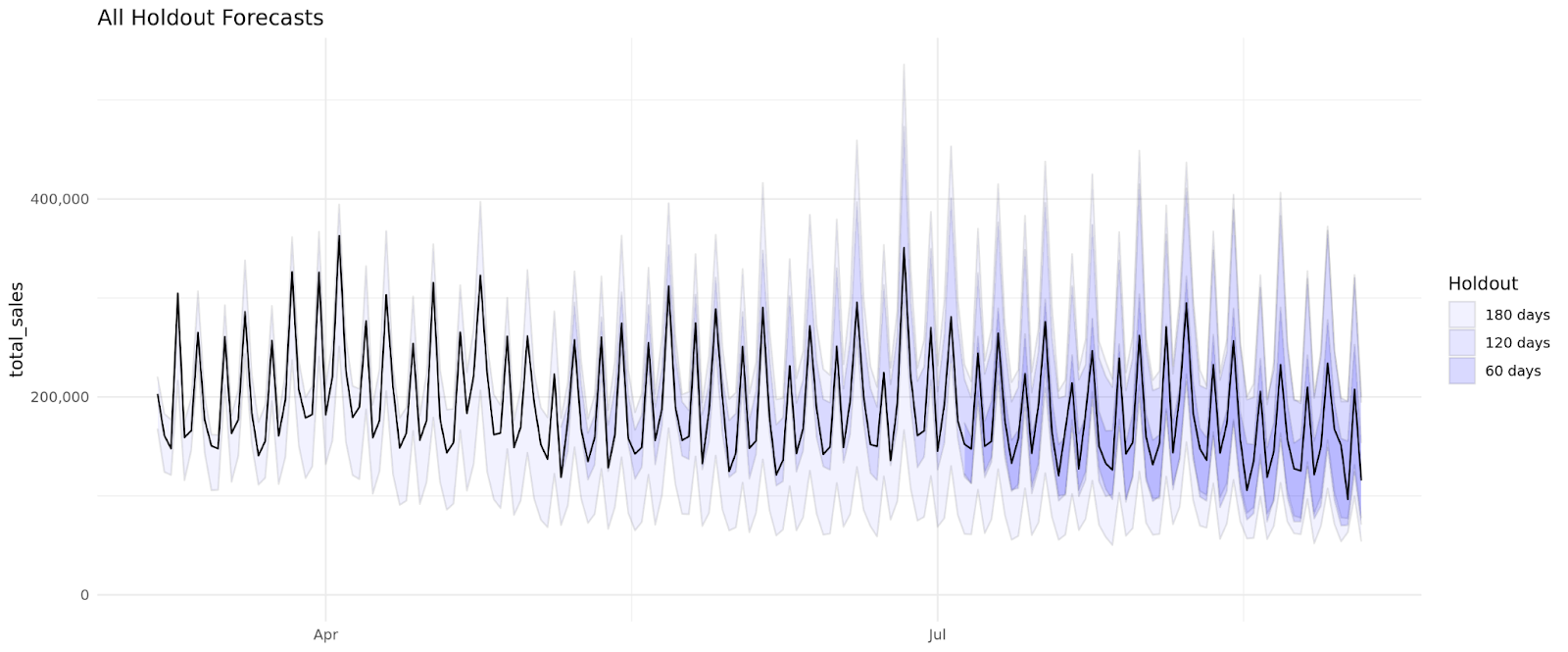
To perform a backwards holdout test, we do something similar to what we did in the stability loop where we will subset the data back in time as if it was one month ago, two months ago, etc. (up to six months back). Then we will verify that the actuals from the predictions from those models fall within the range of uncertainty
The difficulty score used in the holdout difficulty is measured as the square root of the sum of squared differences between spend in the forecast period and spend in the previous period. This is a metric of the amount that spending patterns changed between in-sample data and forecasted data.
Example: backwards holdout test results
The process of developing your model is an ongoing one. We have now covered the process and importance of the model performance checks and the model configuration. The next stage is delivery and ongoing calibration. Your Customer success team will present the initial insights from your model as well as work with you to fine tune your results.